Les bases de données SQL¶
Quand on doit traiter de petits volumes de données, on peut se contenter de les stocker dans des fichiers et d’y accéder directement depuis des programmes écrits en Python. Cette approche est simple et peut donner de bons résultats pour de petits volumes de données ou des données sur lesquelles on doit faire des opérations simples et qu’il ne faut pas souvent modifier. Dans tous les autres cas, il est préférable de faire appel à des gestionnaires de bases de données qui ont été optimisés au fil des années pour stocker et manipuler efficacement de grandes quantités de données.
Aujourd’hui, les bases de données les plus populaires sont les bases de données qui sont dites relationnelles. Une telle base de données est composée d’une ou plusieurs tables qui contiennent de l’information. Chaque table est composée d’un ensemble de lignes qu’on appelle souvent des records. L’information dans une table est aussi divisée en colonnes, chacune de ces colonnes correspondant à un champ ou attribut qui est présent dans chaque record. Une telle base de données est dite relationnelle car il est possible de lier entre eux les lignes qui se trouvent dans des tables différents.
Dans ce document, nous nous focaliserons sur les bases de données utilisant le Structured Query Language (SQL), un langage standardisé supporté par défaut vendeurs de base de données. Pour le projet, nous utiliserons SQLite qui est une implémentation efficace de SQL qui supporte de petites bases de données. SQLite a l’avantage d’être très bien supporté par le langage Python. SQLite est intégré dans les logiciels suivants : Android, iOS, MacOS, Windows10, Firefox, Chrome, Safari, iTunes, Dropbox, …
Une table¶
Les tables constituent le coeur d’une base de données. Chaque table d’une base de données est composée de colonnes et chaque colonne contient de l’information d’un type particulier, comme un nombre, un caractère, une data, une chaîne de caractères, … Une ligne de la table contient une valeur pour chaque colonne.
SQL permet de stocker différents types d’information dans une table. SQLite supporte les types suivants:
INTEGER: un nombre entier
REAL: un nombre réel
TEXT: une chaîne de caractères
BLOB: un séquence de bytes (Binary Large OBject)
NULL: indique l’absence d’une valeur
SQLite peut aussi stocker des dates et des heures en les représentant sous la
forme d’un TEXT, un REAL ou un INTEGER. Des fonctions spécifiques
permettent de manipuler ces dates et heures.
La base de données ci-dessous est composée de quatre colonnes. La première contient des nombres entiers tandis que les trois autres contiennent des chaînes de caractères. Lorsque l’on crée une telle table dans une base de données, il est souvent nécessaire de spécifier la taille de chacun des champs qui est stocké. Ici, on aura par exemple réservé 30 caractères pour le nom et le prénom et 50 pour l’adresse email. La colonne matricule ne peut contenir que des nombres entiers.
matricule |
nom |
prénom |
|
17 |
Durand |
Jules |
|
42 |
Tartempion |
Emilie |
|
95 |
Durant |
Antoine |
Lorsque l’on conçoit une base de données, on en définit son schéma, c’est-à-dire la structure de chacune des tables et les liens qui existent entre ces tables. Pour pouvoir faire des liens entre des tables, il est important de pouvoir identifier une ligne d’une table de façon unique. Dans la table des étudiants présentée ci-dessous, cela peut se faire en utilisant le matricule ou l’adresse email de l’étudiant. Cet identifiant unique est appelé une clé primaire (primary key en anglais). Cette clé peut être une colonne de la table ou dans certains cas un groupe de colonnes de la table. Dans la table ci-dessus, les noms et prénoms des étudiants ne sont pas de bonnes clés primaires puisque rien ne garantir leur unicité.
Cette clé primaire peut servir de lien vers une autre table. Considérons une table qui reprend les inscriptions à un programme universitaire. Celle-ci pourrait être structurée comme suit:
programme |
étudiant |
année |
SINF1BA |
17 |
2 |
SINF11 |
33 |
1 |
SINF1BA |
42 |
3 |
Dans ce cas, le matricule de la première table sert de clé externe (foreign key en anglais) dans la seconde table. Des relations plus complexes peuvent être créées entre les différentes tables d’une base de données. Le principe de base lors de la création d’un schéma de base de données est d’encoder une information à un seul endroit dans la base de données et d’utiliser des clés externes pour faire référence à la table contenant l’information mère. Les règles de création d’un base de données sortent du cadre de ce projet et seront abordées dans le cadre du cours de bases de données.
Utilisation de SQL depuis Python¶
SQL est un langage standardisé qui est supporté par de nombreuses bases de données et de nombreux langages de programmation. Il y a de nombreuses façons d’accéder à une base de données en SQL. Dans le cadre de ce tutoriel, nous utiliserons la base de données d’exemple baptisée Chinook qui est notamment utilisée par le site https://sqlitetutorial.net.
Cette base de données peut être téléchargée depuis : https://github.com/lerocha/chinook-database/raw/master/ChinookDatabase/DataSources/Chinook_Sqlite.sqlite
Une première façon d’explorer son contenu est d’utiliser un logiciel disposant d’une interface graphique tel que sqlitebrowser.
Utilisation de sqlitebrowser sur la base de données Chinook¶
Un outil tel que sqlitebrowser est intéressant pour sa balader dans une nouvelle base de données ou modifier son contenu, mais c’est nettement moins flexible que d’écrire un programme pour l’interroger.
Il est aussi possible d’accéder à la base de données depuis l’interface en ligne de commande de sqlite.
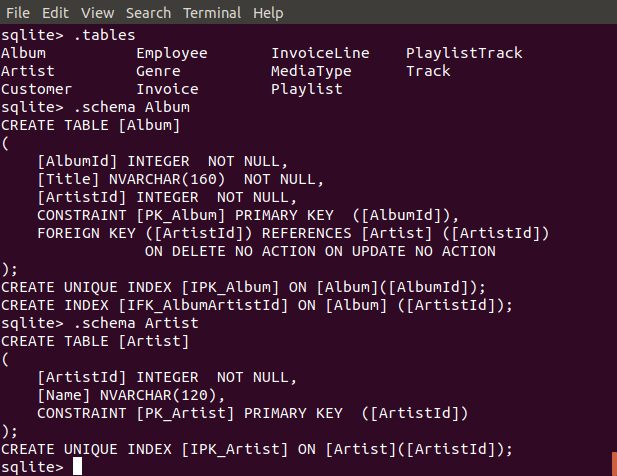
Utilisation de sqlite en ligne de commande¶
La commande .tables permet de lister les tables se trouvant dans la
base de données. La base de données Chinook contient notamment
de l’information relative à des albums musicaux. Celle-ci est structurée
dans plusieurs tables. La commande .schema permet de voir les commandes
qui ont été utilisées pour créer cette table de la base de données. Nous
reviendrons sur les principales commandes de SQL en nous concentrant sur
celles qui permettent d’extraire des données.
Connexion à une base de données SQL¶
SQLite est directement inclus dans la distribution de Python. Vous pouvez
donc l’utiliser en important simplement le package sqlite3 dans
vos programmes Python. La première étape pour utiliser une base
de données est de s’y connecter. Dans une entreprise, cela peut nécessiter
de connaître le nom du serveur sur laquelle elle tourne et d’obtenir des
informations telles qu’un nom d’utilisateur ou un mot de passe. Comme SQLite
utilise un fichier unique sur l’ordinateur pour stocker la base de données,
il suffit de spécifier le nom de ce fichier pour y accéder via la
fonction sqlite3.connect. Cette fonction retourne un objet Connection
qui permet d’interagir avec la base de données. L’envoi de commandes SQL
se fait en utilisant un objet Cursor qui est obtenu grâce à la méthode
cursor(). C’est via cet objet que toutes les interactions avec la
base de données se feront depuis le programme Python. Lorsque le programme
a fini d’utiliser la base de données, il doit fermer la connexion
avec la méthode close(). Si celle-ci a été modifiée, il faut penser
à faire appel à commit() pour forcer l’écriture des modifications.
#!/usr/bin/env python
import sqlite3
# Accès à la base de données
conn = sqlite3.connect('Chinook_Sqlite.sqlite')
# Le curseur permettra l'envoi des commandes SQL
cursor = conn.cursor()
# utilisation de la base de données
# Si on a fait des modifications à la base de données
conn.commit()
# Toujours fermer la connexion quand elle n'est plus utile
conn.close()
Création d’une base de données SQL¶
La première étape est de créer une base de données. Commençons par une base de données comprenant une seule table. Notre base de données va stocker les élèves d’une classe. Elle contient les informations suivantes:
Nom de l’élève (chaîne de caractères)
Prénom de l’élève (chaîne de caractères)
Année de naissance (nombre entier)
Moyenne des points (nombre réel)
Matricule (entier)
La clé primaire de cette table est le matricule qui est unique pour chaque élève. La table peut être créée par la commande suivante :
cursor.execute('''CREATE TABLE CLASSE
(
MATRICULE INT PRIMARY KEY NOT NULL,
NOM TEXT NOT NULL,
PRENOM TEXT NOT NULL,
AGE INT NOT NULL,
POINTS REAL
);''')
Dans ce schéma, on indique que les champs MATRICULE, NOM, PRENOM,
et AGE sont obligatoires en spécifiant qu’ils ne peuvent pas avoir la valeur
NULL. Le moteur de base de données vérifiera que cette contrainte est
respectée lors de toute modification de la base de données.
Dans l’exemple ci-dessus, nous pouvons observer que la clé primaire est MATRICULE.
Grace à cet attribut, nous pouvons identifier de manière unique chaque ligne de
cette table. Dans un monde où chaque étudiant pourrait être identifié par la
composition de son NOM et PRENOM, nous pourrions définir une clé primaire composée,
comme indiqué dans l’exemple ci-dessous:
cursor.execute('''CREATE TABLE CLASSE
(
MATRICULE INT NOT NULL,
NOM TEXT NOT NULL,
PRENOM TEXT NOT NULL,
AGE INT NOT NULL,
POINTS REAL ,
PRIMARY KEY (NOM, PRENOM)
);''')
Cependant cette solution de clé composée n’est pas optimale, car comme annoncé plus haut, nous pourrions rencontrer des étudiants portant les mêmes noms et prénoms. Et nous ne pourrions plus les identifier de manière unique.
Ajout d’information dans une base de données SQL¶
La table étant créée, nous pouvons maintenant y ajouter de l’information.
Cela se fait en utilisant la commande SQL INSERT INTO qui prend
comme arguments un nom de table, une liste d’identifiants de colonnes, et
une liste de valeurs précédée du mot-clé VALUES.
La première façon d’insérer des données dans une table SQL est de fournir la commande avec toutes les données à insérer comme dans l’exemple ci-dessous.
# Encodage direct des données
cursor.execute('''INSERT INTO CLASSE (MATRICULE, NOM, PRENOM, AGE, POINTS)
VALUES (1, 'Durant', 'Emilie', '8', 73.5)''')
Lorsque l’on doit insérer plusieurs données dans la table, par exemple le
contenu d’une liste Python ou d’un dictionnaire, il est plus facile
d’utiliser des espaces réservés qui sont identifiés dans la commande
par le caractère ?. La librairie sqlite3 remplace ces espaces réservés
par les valeurs se trouvant dans la liste passée en argument.
# Données passées via des espaces réservés
mat=2
nom="Durand"
prenom="Joséphine"
age=7
moyenne=88.65
cursor.execute('''INSERT INTO CLASSE (MATRICULE, NOM, PRENOM, AGE, POINTS)
VALUES (?, ?, ?, ?, ?)''',
(mat,nom,prenom,age,moyenne) )
On peut faire de même avec un dictionnaire et indiquer dans la chaîne de caractères qui contient la commande SQL des noms de clés et passer en second argument un dictionnaire définissant un valeur pour chacune de ces clés. Dans la commande SQL, chaque clé est précédée du caractère :. Cette forme peut être utile lorsqu’il faut insérer le contenu d’un dictionnaire dans une table SQL.
# Données passées via des espaces nommés
mat=4
nom="Tartempion"
prenom="Jean"
age=9
moyenne=68.65
cursor.execute('''INSERT INTO CLASSE (MATRICULE, NOM, PRENOM, AGE, POINTS)
VALUES (:mat, :nom, :prenom, :age, :points)''',
{"mat":mat,"nom":nom,"prenom":prenom,"age":age,"points":moyenne} )
Lorsque sqlite3 traite une commande d’insertion, la librairie vérifie
que les contraintes spécifiées à la création de la table sont respectées.
Ces contraintes peuvent porter sur la présence de valeurs nulles, la
taille des chaînes de caractères, etc. L’exemple ci-dessous montre une
insertion d’un record qui ne contient pas de valeur pour le champ POINTS.
Cette insertion est acceptée puisqu’elle est conforme à la définition
de la table CLASSE.
cursor.execute('''INSERT INTO CLASSE (MATRICULE, NOM, PRENOM, AGE)
VALUES (12, 'Dupont', 'Jules', 9)''')
Par contre, il n’est pas possible d’insérer dans la base de données un record
qui ne contient pas de valeur pour le champ AGE.
cursor.execute('''INSERT INTO CLASSE (MATRICULE, NOM, PRENOM)
VALUES (9, 'Dupont', 'Emile')''')
# fails:
# Traceback (most recent call last):
# File "db-insert2.py", line 49, in <module>
# VALUES (9, 'Dupont', 'Emile')''')
# sqlite3.IntegrityError: NOT NULL constraint failed: CLASSE.AGE
Recherche d’information dans une base de données SQL¶
Dans le cadre de ce projet, vous vous concentrerez sur l’extraction
d’information se trouvant dans une base de données existante, mais vous ne
la modifierez normalement pas. En SQL, l’extraction d’information se fait
en utilisant la requête SELECT. La forme générique d’une requête
SELECT est SELECT <liste de colonnes> FROM <table> WHERE <conditions>
où <liste de colonnes> est une liste d’identifiant de colonnes,
<table> le nom d’une table et <conditions> une série de conditions
qui permettent de sélectionner les données à extraire.
La forme la plus simple de la requête est de ne pas écrire de condition.
print("Prénom\t Nom")
for row in cursor.execute("SELECT PRENOM, NOM from CLASSE"):
print(row[0], "\t", row[1])
Ce code affiche sur sa sortie standard les étudiants de la classe.
Prénom Nom
Emilie Durant
Joséphine Durand
Jean Tartempion
Jules Dupont
Plutôt que de spécifier les colonnes qui sont demandées, il est aussi possible
d’obtenir une copie du contenu de toute la table en utilisant * comme
identifiant de colonnes.
for row in cursor.execute("SELECT * from CLASSE"):
print(row)
Ce code retourne la liste des attributs contenus dans la table CLASSE.
(1, 'Durant', 'Emilie', 8, 73.5)
(2, 'Durand', 'Joséphine', 7, 88.65)
(4, 'Tartempion', 'Jean', 9, 68.65)
(12, 'Dupont', 'Jules', 9, None)
En utilisant les conditions de la requête SELECT, il est possible de
filtrer les données avant de les extraire. SQL supporte de nombreux filtres.
Il est tout d’abord possible de comparer la valeur d’un champ de la
base de données. Les comparaisons suivantes sont supportées :
=: égal
<>: différent
>: plus grand que (ainsi que>=)
<: plus petit que (ainsi que<=)
A titre d’exemple, le code ci-dessous permet d’extraire les étudiants qui ont une moyenne supérieure à 70.
for row in cursor.execute("SELECT * from CLASSE WHERE POINTS>70"):
print(row)
Plusieurs conditions peuvent être combinées sous la forme d’une expression
booléenne en utilisant les opérateurs AND, OR et NOT habituels.
Parfois, une requête SQL retourne de nombreux résultats identiques. Supposons que l’on cherche à savoir les différents âges des étudiants de la classe sans avoir besoin de connaître le nombre d’étudiants ayant chaque âge.
for row in cursor.execute("SELECT AGE from CLASSE "):
print(row)
Cette requête extrait tous les âges (différents de NULL) de notre table. Dans une grande base de données, cette liste peut être fort longue.
(8,)
(7,)
(9,)
(9,)
Une meilleure approche est d’indiquer dans la requête SQL que l’on souhaite juste obtenir les valeurs distinctes.
for row in cursor.execute("SELECT DISTINCT AGE from CLASSE "):
print(row)
SQL supporte des conditions plus complexes. Il est notamment possible
de rechercher si un champ est NULL. La requête ci-dessous va
extraire de notre table le record dont le champ POINTS est NULL
et afficher ('Dupont', 12).
for row in cursor.execute("SELECT NOM, MATRICULE from CLASSE WHERE POINTS IS NULL"):
print(row)
Les conditions d’une requête SQL peuvent aussi porter sur le contenu
des chaînes de caractères. L’approche est assez simple comparée aux
expressions régulières que l’on retrouve dans Python, mais elle permet
déjà de faire une pré-traitement de certaines données. Dans la chaîne
de caractères d’une condition, le caractère spécial _ correspond à n’importe
quel caractère tandis que le caractère % peut remplacer n’importe quelle
suite de caractères. Les requêtes ci-dessous permettent d’extraire de la base
de données les élèves dont le nom de famille contient certains caractères.
print ("Requête : Du%")
for row in cursor.execute("SELECT NOM, PRENOM from CLASSE WHERE NOM LIKE 'Du%'"):
print(row)
print ("Requête : Du%t")
for row in cursor.execute("SELECT NOM, PRENOM from CLASSE WHERE NOM LIKE 'Du%t'"):
print(row)
print ("Requête : D_____t")
for row in cursor.execute("SELECT NOM, PRENOM from CLASSE WHERE NOM LIKE 'D____t'"):
print(row)
Résultat affiché par ce code.
Requête : Du%
('Durant', 'Emilie')
('Durand', 'Joséphine')
('Dupont', 'Jules')
Requête : Du%t
('Durant', 'Emilie')
('Dupont', 'Jules')
Requête : D_____t
('Durant', 'Emilie')
('Dupont', 'Jules')
Le langage SQL contient de nombreuses fonctions que l’on peut utiliser dans
une requête SQL. Tout d’abord, il est possible appliquer les opérations
arithmétiques classiques (+, -, * et /) aux valeurs ou
variables numériques.
for row in cursor.execute("SELECT NOM, POINTS+10 from CLASSE"):
print(row)
Cette requête affiche la sortie suivante :
('Durant', 83.5)
('Durand', 98.65)
('Tartempion', 78.65)
('Dupont', None)
SQL supporte également des fonctions qui permettent de manipuler les chaînes de caractères comme dans n’importe quel autre langage de programmation. Par exemple :
length(X)qui retourne la longueur de la chaîne de caractèresX
instr(X,Y)qui retourne la première occurrence de la chaîneYdansX
lower(X)qui transformeXen minuscules (voir aussiupper(X))
substr(X,Y,Z)qui retourne la sous-chaîne de caractères deXqui démarre au caractèreYet es longue deZcaractères
trim(X,Y)qui retire du début et de la fin de la chaîneXtous les caractères qui se trouvent dans la chaîneY
Les autres fonctions sont décrites dans le manuel de SQLite: https://sqlite.org/lang.html
SQLite support également des fonctions spécifiques à la manipulation des dates. Celles-ci sont décrites dans le manuel de SQLIte: https://sqlite.org/lang_datefunc.html
Parmi les fonctions supportées par SQLite, les fonctions d’agrégation sont particulières car elles permettent de réaliser des calculs sur les résultats d’une requête. Voici quelques exemples qui illustrent leur utilisation. Elles sont décrites dans le manuel de SQLite: https://sqlite.org/lang_aggfunc.html.
for row in cursor.execute("SELECT 'Etudiants', avg(POINTS) from CLASSE"):
print(row)
# Affiche ('Etudiants', 76.93333333333334)
for row in cursor.execute("SELECT count(*) from CLASSE WHERE NOM LIKE 'D%'"):
print(row)
# Affiche (3,)
for row in cursor.execute("SELECT max(POINTS) from CLASSE "):
print(row)
# Affiche (88.65,)
for row in cursor.execute("SELECT group_concat(NOM,'/') from CLASSE WHERE NOM LIKE '%t'"):
print(row)
# Affiche ('Durant/Dupont',)
Lorsque l’on manipule une base de données, il est parfois nécessaire de
connaître le nombre de fois qu’une valeur distincte est présente dans la base
de données, sans nécessairement devoir charger toutes ces valeurs. Cela
peut se faire en utilisant le modifier DISTINCT. L’exemple ci-dessous
affiche (4, ) ce qui indique qu’il y a quatre noms distincts dans notre
table d’exemple.
for row in cursor.execute("SELECT count(DISTINCT(NOM)) from CLASSE"):
print(row)
Jusqu’à présent, nous avons manipulé une base de données minuscule contenant une seule table. Pour aborder des utilisations plus avancées de SQL, nous allons maintenant travailler sur la base de données Chinook qui a été présentée plus tôt. Cette base de données comprend plusieurs tables.
sqlite> .tables
Album Employee InvoiceLine PlaylistTrack
Artist Genre MediaType Track
Customer Invoice Playlist
Dans la suite de ce document, nous allons utiliser les tables Album,
Artist et Track.
La table Artist est très simple, elle contient une liste d’artistes
et associe à chacun d’entre eux un identifiant.
sqlite> .schema Artist
CREATE TABLE [Artist]
(
[ArtistId] INTEGER NOT NULL,
[Name] NVARCHAR(120),
CONSTRAINT [PK_Artist] PRIMARY KEY ([ArtistId])
);
CREATE UNIQUE INDEX [IPK_Artist] ON [Artist]([ArtistId]);
La requête ci-dessous permet de visualiser un sous-ensemble de cette table qui contient 275 artistes.
print("Table Artist")
i=0
for row in cursor.execute("SELECT ArtistId, Name FROM Artist "):
if i<10:
print(row)
i=i+1
print("Nombre total de lignes: ",i)
Table Artist
(1, 'AC/DC')
(2, 'Accept')
(3, 'Aerosmith')
(4, 'Alanis Morissette')
(5, 'Alice In Chains')
(6, 'Antônio Carlos Jobim')
(7, 'Apocalyptica')
(8, 'Audioslave')
(9, 'BackBeat')
(10, 'Billy Cobham')
Nombre total de lignes: 275
Il est intéressant de noter que si l’on cherche à extraire uniquement
quelques lignes de la base de données, il suffit d’utiliser le paramètre
LIMIT comme dans l’exemple ci-dessous.
print("Table Artist")
for row in cursor.execute("SELECT ArtistId, Name FROM Artist LIMIT 10"):
print(row)
La table Album contient une liste d’albums de musique avec des
références vers la table Artist. Afin de définir cette contrainte
sur votre schéma de base de données, vous devez ajouter une ligne
FOREIGN KEY (ArtistId) REFERENCES Artist (ArtistId) lors de la
création de votre table, comme indiqué dans la console ci-dessous.
Chaque album est associé à un identifiant unique.
sqlite> .schema Album
CREATE TABLE [Album]
(
[AlbumId] INTEGER NOT NULL,
[Title] NVARCHAR(160) NOT NULL,
[ArtistId] INTEGER NOT NULL,
CONSTRAINT [PK_Album] PRIMARY KEY ([AlbumId]),
FOREIGN KEY ([ArtistId]) REFERENCES [Artist] ([ArtistId])
ON DELETE NO ACTION ON UPDATE NO ACTION
);
CREATE UNIQUE INDEX [IPK_Album] ON [Album]([AlbumId]);
CREATE INDEX [IFK_AlbumArtistId] ON [Album] ([ArtistId]);
Cette table contient 347 lignes.
print("Table Album")
i=0
for row in cursor.execute("SELECT AlbumId, Title, ArtistId FROM Album "):
if i<10:
print(row)
i=i+1
print("Nombre total de lignes: ",i)
Table Album
(1, 'For Those About To Rock We Salute You', 1)
(2, 'Balls to the Wall', 2)
(3, 'Restless and Wild', 2)
(4, 'Let There Be Rock', 1)
(5, 'Big Ones', 3)
(6, 'Jagged Little Pill', 4)
(7, 'Facelift', 5)
(8, 'Warner 25 Anos', 6)
(9, 'Plays Metallica By Four Cellos', 7)
(10, 'Audioslave', 8)
Nombre total de lignes: 347
La table Track est la plus complexe. Elle contient les informations
relatives aux chansons qui se trouvent sur les différents albums de musique.
sqlite> .schema Track
CREATE TABLE [Track]
(
[TrackId] INTEGER NOT NULL,
[Name] NVARCHAR(200) NOT NULL,
[AlbumId] INTEGER,
[MediaTypeId] INTEGER NOT NULL,
[GenreId] INTEGER,
[Composer] NVARCHAR(220),
[Milliseconds] INTEGER NOT NULL,
[Bytes] INTEGER,
[UnitPrice] NUMERIC(10,2) NOT NULL,
CONSTRAINT [PK_Track] PRIMARY KEY ([TrackId]),
FOREIGN KEY ([AlbumId]) REFERENCES [Album] ([AlbumId])
ON DELETE NO ACTION ON UPDATE NO ACTION,
FOREIGN KEY ([GenreId]) REFERENCES [Genre] ([GenreId])
ON DELETE NO ACTION ON UPDATE NO ACTION,
FOREIGN KEY ([MediaTypeId]) REFERENCES [MediaType] ([MediaTypeId])
ON DELETE NO ACTION ON UPDATE NO ACTION
);
CREATE UNIQUE INDEX [IPK_Track] ON [Track]([TrackId]);
CREATE INDEX [IFK_TrackAlbumId] ON [Track] ([AlbumId]);
CREATE INDEX [IFK_TrackGenreId] ON [Track] ([GenreId]);
CREATE INDEX [IFK_TrackMediaTypeId] ON [Track] ([MediaTypeId]);
Cette table contient 3503 morceaux de musique.
print("Table Track")
i=0
for row in cursor.execute("SELECT TrackId, Name, AlbumId, MediaTypeId, GenreId, Composer, Milliseconds, Bytes, UnitPrice FROM Track "):
if i<10:
print(row)
i=i+1
print("Nombre total de lignes: ",i)
Table Track
(1, 'For Those About To Rock (We Salute You)', 1, 1, 1, 'Angus Young, Malcolm Young, Brian Johnson', 343719, 11170334, 0.99)
(2, 'Balls to the Wall', 2, 2, 1, None, 342562, 5510424, 0.99)
(3, 'Fast As a Shark', 3, 2, 1, 'F. Baltes, S. Kaufman, U. Dirkscneider & W. Hoffman', 230619, 3990994, 0.99)
(4, 'Restless and Wild', 3, 2, 1, 'F. Baltes, R.A. Smith-Diesel, S. Kaufman, U. Dirkscneider & W. Hoffman', 252051, 4331779, 0.99)
(5, 'Princess of the Dawn', 3, 2, 1, 'Deaffy & R.A. Smith-Diesel', 375418, 6290521, 0.99)
(6, 'Put The Finger On You', 1, 1, 1, 'Angus Young, Malcolm Young, Brian Johnson', 205662, 6713451, 0.99)
(7, "Let's Get It Up", 1, 1, 1, 'Angus Young, Malcolm Young, Brian Johnson', 233926, 7636561, 0.99)
(8, 'Inject The Venom', 1, 1, 1, 'Angus Young, Malcolm Young, Brian Johnson', 210834, 6852860, 0.99)
(9, 'Snowballed', 1, 1, 1, 'Angus Young, Malcolm Young, Brian Johnson', 203102, 6599424, 0.99)
(10, 'Evil Walks', 1, 1, 1, 'Angus Young, Malcolm Young, Brian Johnson', 263497, 8611245, 0.99)
Nombre total de lignes: 3503
Avec ce trois tables, il est possible d’explorer des requêtes SQL plus complexes.
Commençons par essayer d’extraire de la base de données les albums d’un artiste donné. Pour cela, il faut d’abord extraire l’identifiant de cet
artiste de la table Artist puis faire une requête dans la table
Album comme la suivante:
print("Albums d'AC/DC")
i=0
for row in cursor.execute("SELECT Title FROM Album WHERE ArtistId=1 "):
if i<10:
print(row)
i=i+1
print("Nombre total de lignes: ",i)
Cette requête affiche:
Albums d'AC/DC
('For Those About To Rock We Salute You',)
('Let There Be Rock',)
Nombre total de lignes: 2
Ce n’est pas très efficace au niveau de l’utilisation de la base
de données. Il faut en effet d’abord consulter la base de données
pour connaître l’identifiant de l’artiste et ensuite rechercher
celui-ci dans la table Album. Si l’on veut rechercher les albums
de plusieurs artistes, la clause WHERE peut prendre comme argument
une liste d’identifiants comme dans l’exemple ci-dessous.
print("Albums d'AC/DC ou Aerosmith")
i=0
for row in cursor.execute("SELECT Title FROM Album WHERE ArtistId in (1, 3) "):
if i<10:
print(row)
i=i+1
print("Nombre total de lignes: ",i)
Albums d'AC/DC ou Aerosmith
('For Those About To Rock We Salute You',)
('Let There Be Rock',)
('Big Ones',)
Nombre total de lignes: 3
Cette approche peut être étendue pour par exemple extraire de la base
de données tous les albums d’un artiste dont le nom commence par A.
print("Ids des artistes dont le nom débute par A")
artistes=[]
for row in cursor.execute("SELECT ArtistId FROM Artist WHERE Name LIKE 'A%'"):
artistes.append(row[0])
print(artistes)
print("Albums d'artistes dont le nom débute par A")
i=0
for row in cursor.execute("SELECT Title FROM Album WHERE ArtistId in {}".format(tuple(artistes))):
if i<10:
print(row)
i=i+1
print("Nombre total de lignes: ",i)
Même si ce code affiche le résultat demandé, ce n’est pas la bonne approche.
Ids des artistes dont le nom débute par A
[1, 2, 3, 4, 5, 6, 7, 8, 26, 43, 159, 161, 166, 197, 202, 206, 209, 214, 215, 222, 230, 239, 243, 252, 257, 260]
Albums d'artistes dont le nom débute par A
('For Those About To Rock We Salute You',)
('Let There Be Rock',)
('Balls to the Wall',)
('Restless and Wild',)
('Big Ones',)
('Jagged Little Pill',)
('Facelift',)
('Warner 25 Anos',)
('Chill: Brazil (Disc 2)',)
('Plays Metallica By Four Cellos',)
Nombre total de lignes: 27
La bonne approche est d’utiliser SQL pour générer aussi la liste des
artistes dans une seule requête. Il est en effet possible de mettre
dans la clause WHERE d’une requête une autre requête SQL qui
elle aussi produit une liste.
print("Albums d'artistes dont le nom débute par A")
i=0
for row in cursor.execute('''SELECT Title FROM Album WHERE ArtistId in (
SELECT ArtistId FROM Artist WHERE Name LIKE 'A%'
)'''):
if i<10:
print(row)
i=i+1
print("Nombre total de lignes: ",i)
Cette requête fournit le résultat attendu.
Albums d'artistes dont le nom débute par A
('For Those About To Rock We Salute You',)
('Let There Be Rock',)
('Balls to the Wall',)
('Restless and Wild',)
('Big Ones',)
('Jagged Little Pill',)
('Facelift',)
('Warner 25 Anos',)
('Chill: Brazil (Disc 2)',)
('Plays Metallica By Four Cellos',)
Nombre total de lignes: 27
Il est évidemment possible d’utiliser une requête SQL dans la clause
WHERE de la seconde requête et ainsi de suite.
SQL permet aussi de contrôler l’ordre dans lequel les données sont
retournée. Par défaut, celles-ci sont retournées dans un ordre
non spécifié, mais on peut forcer un ordonnancement sur base de certaines
colonnes en utilisant le paramètre ORDER BY après la liste des
tables (ou après la clause WHERE si celle-ci est présente).
for row in cursor.execute("SELECT AlbumId, Title FROM Album ORDER BY Title ASC LIMIT 5"):
print(row)
Cette requête affiche les noms d’albums dans l’ordre alphabétique.
(156, '...And Justice For All')
(257, '20th Century Masters - The Millennium Collection: The Best of Scorpions')
(296, 'A Copland Celebration, Vol. I')
(94, 'A Matter of Life and Death')
(95, 'A Real Dead One')
Il est aussi possible de spécifier un ordre sur une première colonne et une seconde en croissant ou décroissant.
for row in cursor.execute("SELECT TrackId, Name, Milliseconds FROM Track ORDER BY Milliseconds DESC, Name ASC LIMIT 5"):
print(row)
Cette requête affiche les noms des cinq plus longs morceaux de la base de données.
(2820, 'Occupation / Precipice', 5286953)
(3224, 'Through a Looking Glass', 5088838)
(3244, 'Greetings from Earth, Pt. 1', 2960293)
(3242, 'The Man With Nine Lives', 2956998)
(3227, 'Battlestar Galactica, Pt. 2', 2956081)
SQL permet aussi de combiner des informations qui sont stockées dans plusieurs tables différentes. Celle-ci s’appelle généralement une jointure dans la terminologie SQL. Une telle jointure est illustrée dans l’exemple ci-dessous.
print("Albums et artistes ")
i=0
for row in cursor.execute("SELECT Album.Title, Artist.Name FROM Album, Artist WHERE Album.ArtistId=Artist.ArtistId"):
if i<10:
print(row)
i=i+1
print("Nombre total de lignes: ",i)
Cette requête retourne le résultat attendu.
Albums et artistes
('For Those About To Rock We Salute You', 'AC/DC')
('Balls to the Wall', 'Accept')
('Restless and Wild', 'Accept')
('Let There Be Rock', 'AC/DC')
('Big Ones', 'Aerosmith')
('Jagged Little Pill', 'Alanis Morissette')
('Facelift', 'Alice In Chains')
('Warner 25 Anos', 'Antônio Carlos Jobim')
('Plays Metallica By Four Cellos', 'Apocalyptica')
('Audioslave', 'Audioslave')
Nombre total de lignes: 347
Soyez cependant attentif au fonctionnement d’un jointure en SQL. Conceptuellement, il faut imagine qu’une jointure se déroule comme suit:
La base de données extrait les lignes des deux tables sélectionnées et construit toutes les paires de lignes contenant une ligne de la première et une ligne de la seconde
La base de données filtre les lignes intéressantes sur base des clauses
WHERELa base de données retourne les colonnes indiquées dans le
SELECT
Il faut garder ce mode de fonctionnement en mémoire lorsque l’on utilise une jointure SQL. La requête ci-dessous est un bon contre-exemple de ce qu’il ne faut pas faire.
i=0
for row in cursor.execute("SELECT Album.Title, Artist.Name FROM Album, Artist "):
if i<10:
print(row)
i=i+1
print("Nombre total de lignes: ",i)
('For Those About To Rock We Salute You', 'AC/DC')
('For Those About To Rock We Salute You', 'Accept')
('For Those About To Rock We Salute You', 'Aerosmith')
('For Those About To Rock We Salute You', 'Alanis Morissette')
('For Those About To Rock We Salute You', 'Alice In Chains')
('For Those About To Rock We Salute You', 'Antônio Carlos Jobim')
('For Those About To Rock We Salute You', 'Apocalyptica')
('For Those About To Rock We Salute You', 'Audioslave')
('For Those About To Rock We Salute You', 'BackBeat')
('For Those About To Rock We Salute You', 'Billy Cobham')
Nombre total de lignes: 95425
Cette requête retourne le produit-cartésien entre les deux tables. Si la première contient N lignes et la secondes M lignes, le résultat en contient N*M ce qui peut être énorme pour de grosses bases de données.
SQLite supporte trois types de jointures: INNER JOIN, LEFT JOIN
et CROSS JOIN. Il est intéressant de voir sur quelques exemples
comment ces jointures se comportent.
Notre première requête permet d’afficher les artistes avec leurs albums en joignant la table Album` avec la table ``Artist.
for row in cursor.execute("SELECT Artist.Name, Album.Title FROM Album INNER JOIN Artist ON Artist.ArtistId = Album.ArtistId ORDER BY Artist.Name ASC LIMIT 5"):
print(row)
Dans cette requête, le champ Name provient de la table Artist tandis que le champ Title de la table Album. Seules les lignes pour lesquelles le champ ArtistId provenant de la table Artist est identique à celui provenant de la table Album sont affichées.
('AC/DC', 'For Those About To Rock We Salute You')
('AC/DC', 'Let There Be Rock')
('Aaron Copland & London Symphony Orchestra', 'A Copland Celebration, Vol. I')
('Aaron Goldberg', 'Worlds')
('Academy of St. Martin in the Fields & Sir Neville Marriner', 'The World of Classical Favourites')
Des exemples complémentaires sont disponibles dans le tutoriel SQLite: https://www.sqlitetutorial.net/sqlite-inner-join/
Cette jointure permet de combiner l’information de deux tables. Cependant, elle
ne permet pas de lister les artistes qui n’ont pas d’album dans la base de
données car pour ceux-ci, la condition Artist.ArtistId = Album.ArtistId
est toujours fausse puisque la table Album ne contient aucune ligne avec l’identifiant de cet artiste. Si l’on veut obtenir cette information avec
SQLite, il est possible d’utiliser un LEFT JOIN. Cette jointure
fonctionne conceptuellement en extrayant toutes les lignes de la première table (celle dite à gauche) et les lignes qui correspondent à la condition pour la
seconde table (celle dite à droite). Le LEFT JOIN retourne ensuite toutes les lignes qui correspondent à la condition. Si une ligne de la première table n’a pas de ligne correspondante dans la second, SQLite retourne les champs de la première table et NULL pour ceux qui correspondent à la seconde.
for row in cursor.execute("SELECT Artist.Name, Album.Title FROM Artist LEFT JOIN Album ON Artist.ArtistId = Album.ArtistId WHERE Album.Title is NULL ORDER BY Name ASC LIMIT 5"):
print(row)
Cette requête est particulièrement utile pour rechercher des lignes qui existent dans la première table mais pas dans la seconde. Elle retourne:
('A Cor Do Som', None)
('Academy of St. Martin in the Fields, Sir Neville Marriner & William Bennett', None)
("Aerosmith & Sierra Leone's Refugee Allstars", None)
('Avril Lavigne', None)
('Azymuth', None)
D’autres exemples sont présentés dans le tutoriel SQLite: https://www.sqlitetutorial.net/sqlite-left-join/
La dernière jointure supportée par SQLite est appelée CROSS JOIN. Elle
retourne le produit cartésien entre les deux tables et doit être utilisée
avec prudence vu la taille du résultat qu’elle peut retourner.
Avant de terminer ce survol rapide des fonctionnalités de SQL, il est utile
de revenir sur les fonctions qui permettent d’agréger de l’information
extraite d’une base de données SQL. SQLite supporte plusieurs de ces
fonctions dont avg() pour calculer une moyenne, min() et max ou
encore count(). Il est aussi possible de concaténer des chaînes
de caractères avec group_concat(). Lorsque l’on utilise ces fonctions, il est parfois
important de spécifier les champs sur lesquels elles s’appliquent
et comment les résultats doivent être retournés. Pour cela, la clause
optionnelle GROUP BY d’une requête SELECT peut s’avérer utile.
Supposons que l’on cherche à compter le nombre de morceaux présents dans
chaque album de la table Album. Cette table contient de nombreux albums
comme l’indique la requête ci-dessous.
for row in cursor.execute("SELECT AlbumId, Name, TrackId FROM Track ORDER BY AlbumId ASC LIMIT 15"):
print(row)
(1, 'For Those About To Rock (We Salute You)', 1)
(1, 'Put The Finger On You', 6)
(1, "Let's Get It Up", 7)
(1, 'Inject The Venom', 8)
(1, 'Snowballed', 9)
(1, 'Evil Walks', 10)
(1, 'C.O.D.', 11)
(1, 'Breaking The Rules', 12)
(1, 'Night Of The Long Knives', 13)
(1, 'Spellbound', 14)
(2, 'Balls to the Wall', 2)
(3, 'Fast As a Shark', 3)
(3, 'Restless and Wild', 4)
(3, 'Princess of the Dawn', 5)
(4, 'Go Down', 15)
Une approche naïve pour compter les morceaux de chaque album serait d’écrire la requête suivante.
for row in cursor.execute("SELECT AlbumId, COUNT(TrackId) FROM Track LIMIT 5"):
print(row)
Malheureusement celle-ci ne produit pas le résultat attendu.
(1, 3503)
Elle compte les différentes valeurs de TrackId mais non les morceaux
associés à chaque album. Pour obtenir un résultat correct, il faut
demander dans la requête SQL de grouper ensemble les valeurs qui ont
le même TrackId. Cela peut se faire avec le clause GROUP BY comme dans
l’exemple ci-dessous.
for row in cursor.execute("SELECT AlbumId, COUNT(TrackId) FROM Track GROUP BY AlbumId LIMIT 5"):
print(row)
Cette requête produit le résultat attendu.
(1, 10)
(2, 1)
(3, 3)
(4, 8)
(5, 15)
De la même façon, on peut rechercher tous les albums d’un artiste donné.
for row in cursor.execute("SELECT ArtistId, group_concat(Title, ' !! ') FROM Album GROUP BY ArtistId LIMIT 5"):
print(row)
Cette requête produit le résultat attendu.
(1, 'For Those About To Rock We Salute You !! Let There Be Rock')
(2, 'Balls to the Wall !! Restless and Wild')
(3, 'Big Ones')
(4, 'Jagged Little Pill')
(5, 'Facelift')
Il est évidemment possible de combiner une jointure avec la clause
GROUP BY. La requête ci-dessous extrait les cinq albums qui contiennent
le plus de morceaux différents.
for row in cursor.execute("SELECT Album.Title, COUNT(Track.TrackId) FROM Album INNER JOIN Track ON Album.AlbumId = Track.AlbumId GROUP BY Album.AlbumId ORDER BY COUNT(Track.TrackId) DESC LIMIT 5"):
print(row)
Cette requête produit le résultat attendu.
('Greatest Hits', 57)
('Minha Historia', 34)
('Unplugged', 30)
('Lost, Season 3', 26)
('Lost, Season 1', 25)
D’autres exemples sont repris dans la section consacrée à GROUP BY du
site SQLiteTutorial.net : https://www.sqlitetutorial.net/sqlite-group-by/
De nombreux livres et sites web proposés des cours et tutoriels sur l’utilisation des bases de données et de SQL en particulier. En voici quelques uns :
Les dias présentées en TD sont ici.
Note
Méfiez-vous des injections SQL
Avant de terminer, nous devons malheureusement attirer votre attention sur le problème des attaques par Injection SQL. Lorsque l’on développe un serveur web qui utilise une base de données SQL, il faut y être très attentif. Une telle attaque peut se produire lorsqu’un client qui maîtrise parfaitement SQL interagit avec un serveur développé par un programmeur débutant qui n’a pas pris toutes les protections nécessaires.
Dans nos exemples avec SELECT, nous avons utilisé les formes
recommandées par les auteurs de sqlite3. Celles-ci permettent de
passer des valeurs de variables à la requête SELECT sans risquer
d’attaque par injection SQL. Une discussion détaillée de ces attaques
sort du cadre de ce cours, vous pouvez consulter un document
tel que Preventing SQL Injection Attacks si vous souhaitez en savoir plus.