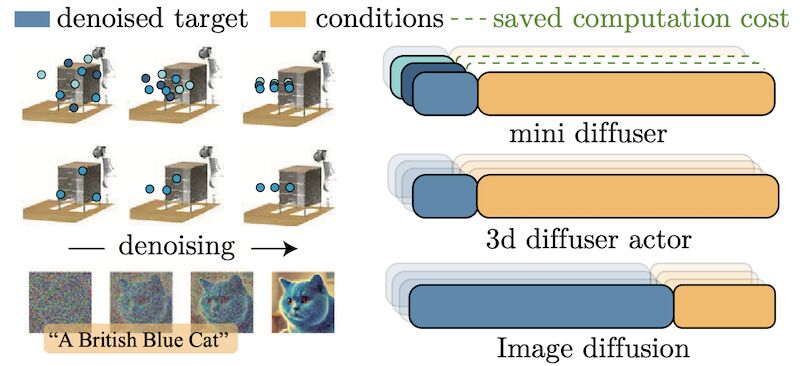
Mini-diffuser reduces by an order of magnitude the time and memory needed to train multi-task vision-language robotic diffusion policies!
Mini Diffuser [1] is a game-changer for training multi-task robotic diffusion policies. We’ve slashed training time by 95% and memory by 93% while maintaining 95% performance! Train a powerful robot policy on a single GPU in just 13 hours.
Check out the code & videos: https://mini-diffuse-actor.github.io
 DOI
DOI arXiv
arXiv Bib
Bib PDF
PDF Video
Video Blog
Blog