New RSS paper: AR-VLA is an autoregressive action expert that boosts the temporal consistency of VLAs and diffusion policies!
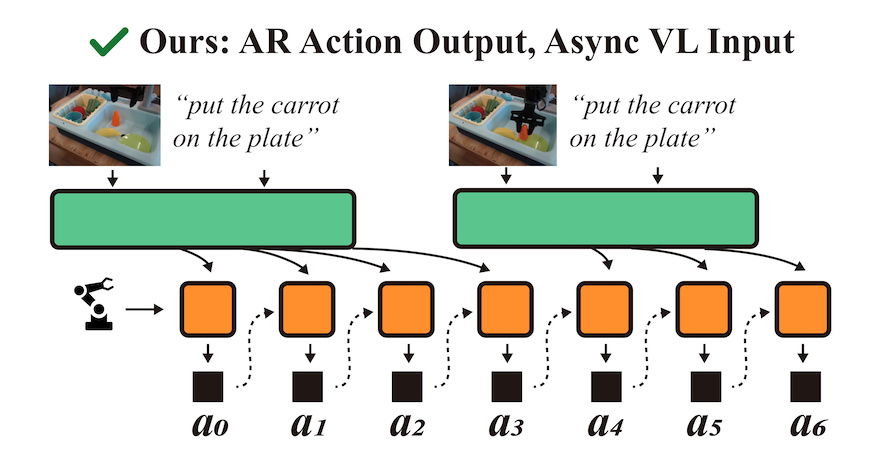
AR-VLA [1] is a standalone autoregressive action expert that generates actions as a continuous causal sequence, conditioned on a (refreshable) vision-language prefix:
✅ Existing VLAs and diffusion policies reset temporal context with each new observation.
✅ Instead, our expert infers actions that are consistent with the long history it maintains internally, as well as with vision-language context that it pulls asynchronously.
✅ This structure addresses the frequency mismatch between fast control and slow perception. It enables efficient independent pre-training of kinematic syntax, and a modular integration with a costly perception backbone.
AR-VLA is a drop-in replacement for traditional chunk-based action heads in specialist or generalist policies. It shows superior history awareness and smoother action trajectories, with success rate equal or superior to SoA!
Check out the code & videos: https://arvla.insait.ai
 arXiv
arXiv Bib
Bib PDF
PDF Blog
Blog