New RSS paper: Multimodal planning and adaptive l-return stabilizes deep imagination in long-horizon visual MPC!
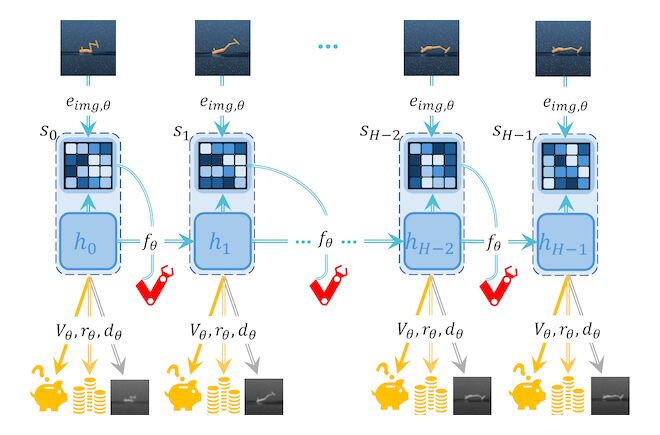
Visual MPC often collapses over long horizons due to mode-averaging and compounding model error. ELVIS (Ensemble-Calibrated Latent Imagination) [1] stabilizes deep imagination to make long-horizon planning practical in latent spaces. 🤖✨
Key technical takeaways for RL practitioners:
✅ Multimodal Planning: Replaces unimodal MPPI with a Gaussian-Mixture MPPI, maintaining multiple coherent trajectory hypotheses to prevent mode-collapse during branching futures in the RSSM.
✅ Adaptive $\lambda_t$-Return: Employs an ensemble of latent critics to compute a UCB-based uncertainty score. This gates a time-varying $\lambda_t$, dynamically trading off look-ahead vs. bootstrapping to truncate rollouts before model drift dominates.
✅ Aligned Objectives: The same uncertainty-aware return used to train the actor-critic prior is used to score candidates in the GMM-MPPI, ensuring tight alignment between the policy prior and the online planner.
ELVIS achieves SOTA on DM Control and demonstrates robust zero-shot transfer to real-world tasks with severe occlusions.
Check out the code & videos: https://github.com/RILEY-REEDUS/ELVIS
 arXiv
arXiv Bib
Bib PDF
PDF Blog
Blog