H2XO
Relieving heavy-duty work with a haptically-controlled robot assistant that learns on the job.

|
Funded by KU Leuven Internal Funds. |

Relieving heavy-duty work with a haptically-controlled robot assistant that learns on the job.
|
|
Funded by KU Leuven Internal Funds. |
The H2XO project aims to develop a bimanual human extender robot to provide physical assistance to workers while learning tasks in real-time for later autonomous execution. The platform integrates a novel haptic interface that relays both kinesthetic and tactile information to the operator, enabling intuitive control over complex tasks. Utilizing AI, the system will continuously learn from human strategies through visual, tactile, and kinesthetic data. The project addresses the need for solutions in industries with physically demanding tasks, aiming to relieve human operators from physical stress while maintaining control and safety, bridging the gap between training and execution phases.
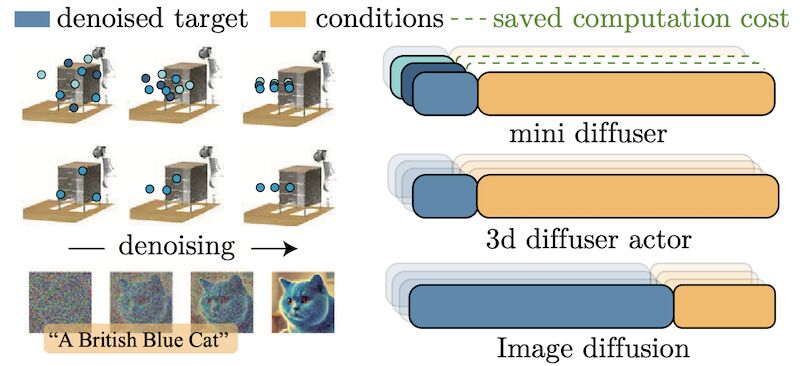
Our first paper Mini Diffuser [1], a novel method significantly improving the efficiency of training multi-task vision-language robotic diffusion policies. Unlike traditional approaches, Mini Diffuser leverages the inherent asymmetry between high-dimensional image conditions and lower-dimensional action targets in robotic tasks. It achieves this through two-level mini-batching, which allows multiple action samples to be paired with a single vision-language condition, and introduces architectural adaptations to prevent information leakage while maintaining full conditioning. This innovation drastically reduces training time and memory usage—by an order of magnitude—while achieving comparable performance to state-of-the-art methods in both simulations and real-world robotic applications.
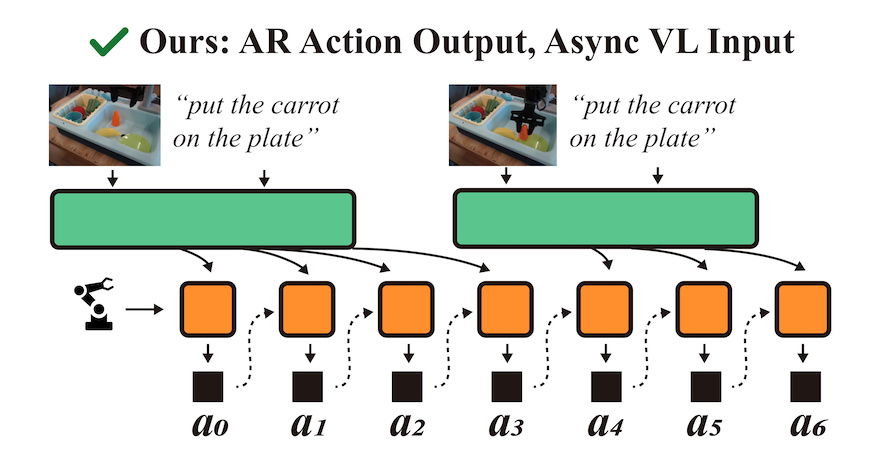
Our second paper, AR-VLA [2], introduces a novel paradigm for vision-language-action models by replacing reactive, snapshot-based action prediction with a true autoregressive action expert that generates actions as a continuous, temporally coherent sequence. Unlike existing approaches that discard history and recompute actions at each step, AR-VLA maintains a persistent internal memory of past states and actions, enabling context-aware control over long horizons. The framework decouples perception and control into asynchronous streams via a Hybrid Key-Value cache and a Dynamic Temporal Re-anchoring mechanism, allowing high-frequency motor execution while integrating lower-frequency vision-language updates. This results in smoother trajectories, improved robustness to latency and partial observability, and superior performance on both generalist and specialist robotic tasks, particularly in scenarios requiring sustained temporal reasoning and recovery from intermediate failures.
 DOI
DOI arXiv
arXiv Bib
Bib PDF
PDF Video
Video Blog
Blog